|
By Anthony Trufanov This is a public service announcement about advantage CP texts. At the outset – I may use a text you wrote or read as an example. That’s not meant as a call-out. This behavior is somehow ubiquitous, and my only record of the behavior is a set of screenshots I’ve saved without teams attached. With that out of the way:
Here are some ‘policy ideas’ that have been proposed this semester in our ‘policy debates’ to ‘solve AI innovation.’ I am quoting these verbatim from CP texts.
One would think it would be obvious why this is terrible, but apparently it needs unpacking. What’s wrong with this picture 1. You are not saying anything. Imagine a judge giving an RFD that starts with “the case was huge, but I didn’t end up thinking the AI race was a serious problem because I could just ‘scale up digital talent pipelines’ instead.” If you take a step back and think about this sentence with your normal, non-debate brain, you will realize that hearing that RFD means either the AFF team dropped the CP or someone in the room is having a stroke. Translating the argument to a real-world conversation is a reasonable litmus test. Imagine writing a paper that will be graded by a professor which hand-waves concerns about innovation based on an unevidenced assertion that governments can simply ‘develop a data strategy that promotes innovation.’ Putting such an under-developed position in a paper will typically be worse than useless; it does nothing to advance your argument, and only serves as evidence of your shallow grasp of the issues you’re discussing. An argument that is highly likely to annoy your judge and which can only help you if it is dropped by your opponent is a bad use of your time and conditionality exposure. 2. Everyone has already thought of that. The government already knows it should scale up digital talent pipelines. It is already trying to promote innovation. Sometimes the way they go about doing this is not very good. But these CP texts do not change the bad ways governments are attacking problems now. They just reiterate that governments should attempt some solution. What could the 2AC possibly be burdened with saying in response, beyond reasserting the importance of the plan? That the government shouldn’t try to solve the problem? It is surely not incumbent on the 2A to guess what random specific policy the 1N was talking about and answer it before the NEG ever explains what it is. 3. More broadly, they do not meaningfully foreclose the status quo. For the NEG to transform something from a ‘would’ question to a ‘should’ question – thus precluding the AFF from responding by saying an actor ‘would’ not act in this way – the NEG must fiat that thing. A good way to determine what is being fiated by an advocacy is look at the inverse – what outcomes does the advocacy’s fiat foreclose? For example, what is foreclosed by ‘increasing resources for R&D?’ Reducing those resources, as well as keeping them the same, are clearly barred. What about a new, 1 cent per decade tax break per million dollars of demonstrated R&D? This is trickier. This is clearly a possible way the CP could be done, but would obviously not meaningfully affect innovation. What about ‘regulate the moon?’ The only scenario barred by this CP’s fiat is a completely unregulated moon. Literally any regulation imaginable – no matter how limited – would cross the bar. To stop bad parts of the status quo, you need to identify what they are and change them. No one wants to give the NEG brownie points for a CP that, substantively, says little more than that the status quo is bad. 4. What did you think the 1N was going to say in CX? Rhetorical question. Whatever the plan for CX was, save everyone some trouble and put it in the text. If your plan was to let your partner flop around like a fish to avoid answering the question, you should not make them introduce that argument. Problem definition – what to do instead What you are really revealing with texts like this is an unclear grasp of the problem you are trying to address. CP solvency operates by identifying parts of the status quo to change, changing them, and arguing that those changes are sufficient to solve the AFF’s harms. If all you know about the AFF’s harms is that they exist, you will have little to say about them other than that you wish they didn’t. This is why I put ‘solve AI innovation’ in scare quotes; the phrase tells you next to nothing about what is wrong with the status quo. To write better texts, you need to reach a more sophisticated understanding of the problem. To accomplish that, you need to ask better ‘why’ questions, and answer them with research. Anthropocentric citizen suits are failing to enforce the Endangered Species Act. Why? Because they undervalue injuries to animals with impacts that are hard to trace to human interests. Why? Because judicial standards for determining whether someone has been injured have been fairly strict, in order to avoid limit standing to those which are proximate to the injury. These questions suggest you need to do some searches about standing reform. AI innovation is low. Why? Is it because the liability risk is so difficult to underwrite that it scares investors away, irrespective of how good the reward might be? Is it because we have a workforce shortage? Why do we have a workforce shortage? Poor quality education? Students not choosing relevant education? Emigration? Do relevant experts find themselves making more money in other sectors? The answers to these questions will tell you what specifically needs to be done in order to ‘scale up digital talent pipelines.’ They could also reveal that ‘digital talent pipelines’ can’t be easily scaled up at all, which will point you to a line of attack against the case. You can also approach the issue from the other direction. Suppose you are debating an AFF like cars. What has to have happened in order to solve the case? Advantage one is about not penalizing manufacturers when they exercised every reasonable precaution and damage still occurred. Advantage two is about penalizing manufacturers when they do not exercise every reasonable precaution to ensure autonomous car cybersecurity. We have already come across some liability schemes with these features on this topic, so the puzzle should not be hard to put together. In short, ADV CPs – like any case defense – improve drastically in quality when they are grounded in deep understanding of the problem you are speaking about. Answers to answers There are a few underlying pathologies and perspectives that make people think vacuous texts are reasonable to introduce. 1. “The AFF internal link is bad, so the CP can be bad too.” When the AFF reads a bad impact card, do you create a new off case page and cover it in verbal diarrhea for 40 seconds of 1NC time to make that point? No – you say that the impact card is bad, you explain why, you move on. What NEG teams that make this excuse are actually talking about are internal links that are easy to fiat out of – those which the AFF is obviously not necessary, even if it is sufficient, to solve. This is a very specific type of defect. You know it when you see it. It usually comes up when the premise of the AFF advantage is that the AFF’s policy causes a different policy. Most bad AFF internal links are bad because they are incoherent, not because they are easy to fiat. Usually something incoherent is actually harder to fiat, since it is difficult to describe the problem that needs to be prevented. When you respond to an incoherent internal link with an incoherent CP, you are replicating the effect of pointing out that it is incoherent, but with extra stupid steps. 2. “The plan is incoherent too.” Maybe you can introduce a vague CP text, provoke the AFF to make a theory argument about it, and cross-apply their theory argument to the plan text. Otherwise, I see no reason why a vague plan would make introducing a nonsense advantage CP a good idea. Maybe you think that you can use the fact that the AFF is hand-waving the solvency debate to hand-wave the NEG solvency debate too. Again, I would suggest that instead of answering stupid with stupid and making the judge equally annoyed at everyone, you should answer stupid with smart and make the judge annoyed at the AFF and happy with you. 3. “But we have a card that is also vague.” Not all cards are equal. Some cards are bad. If you have found an author whose bright idea is to solve AI workforce shortages by simply not having them, they, like you, are not contributing anything valuable to the discourse. 4. “What if they drop it.” What if you hoot like an owl and they drop that? Either your judge will turn their brain off and vote for you on the pure line by line – as they would have irrespective of what noise you made in that section of your speech – or your judge will vote against you because you didn’t say anything. Generally we are looking for arguments that improve our chances of winning relative to making random noises. 5. “Sandbagging helps the NEG.” No, it doesn’t. If the first time the argument is explained is the 1NC, you get the 2NC, 1NR, and 2NR to develop it, and the AFF gets the 2AC, 1AR, and 2AR to answer it. That is balanced. If the first time the argument is explained is the block, you get a 2NR to do everything, while the AFF gets the 1AR and 2AR to answer it. This creates a 2:1 time imbalance against you and makes it so they get to answer your answers, and you don’t get to answer theirs. 6. “Sometimes it really is that simple.” Am I saying that there are no problems in the world that can be solved by throwing money at them? Obviously not. But these problems are the vast minority. They are ones for which structural impediments to the problem’s resolution – whether legal, physical, cultural, or political – have mostly been resolved, leaving only the question of desire for execution. You may have heard of this thing called strained supply chains. The more addled among you 2Ns might be scratching your heads, baffled at why the Biden administration hasn’t just ‘substantially scaled up supply chains’ or ‘overcame supply bottlenecks’ or something by now. But most of you are not stupid. You probably know that the economy is complicated. ‘Supply chains’ is short-hand for a bewilderingly heterogenous set of processes, each of them unique and often mind-bogglingly challenging to optimize. Bottlenecks can come from raw materials you never even knew existed, basic components you’ve never thought about, the depth of our ports, the number of cranes equipped to unload freight containers, the capacity of roads and railroads to move those containers to their destinations. The same dynamics can be seen in topics that 2Ns have become increasingly fond of ‘fiating out of.’ Energy policy is partly about economics, but it’s also about environmental permitting, zoning, federalism, the availability of raw materials to transform capital investment into economic output, the physical ability of different kinds of power generation to provide different grid services, and the availability of specialized labor to build energy infrastructure. The cumulative effect of these complications does not just create a ‘solvency deficit.’ Instead, it makes the effect of such a vacuous text fundamentally unknowable. The range of policies that could be encompassed by such a CP is massive – the range of policy effects nearly infinite. So no, 2N, it usually is not that simple. Sometimes it is. Your track records on identifying those cases are terrible, which is why I am calling for a total and complete shutdown until we can figure out what the hell is going on. 7. “I don’t know how to phrase it better or with more detail.” Go back to the drawing board and cut a card. Sometimes when you have nothing to say, it is better to say nothing at all. Is anyone earnestly defending this? All of the defenses I could think of grant the premise that such CPs are vacuous and do not make a real argument, and reduce to some version of ‘stupid arguments are good if xyz.’ If someone has a justification for this pattern that does NOT grant that premise… I would genuinely be fascinated to hear what it is. I do remember how to write. The end of the year and participating in the NDT has led to a critical mass of thoughts that the internet has to hear. Note while I am obligated to say what I am saying (see title), you are not obligated to click or read beyond this point. Kick rocks if you got beef with the opinions below.
1. Hybrid Tournaments They are not the future. They are bad. In person tournaments are good. Online tournaments are fine. Hybrid tournaments are stupid. Hybrid scheduling (a season long schedule that mixes in person and online) is good. Debate inertia is a hell of a drug. For the love of all that is holy please don’t run your tournament hybrid because the tournament before you did. In a time where debate is declining it seems cruel/detrimental to create barriers to entry (not allowing people to compete online at a tournament they cannot go to in person). I can picture this narrative making the rounds, but in my opinion, it is a cure that is worse than the disease. It is masking. Letting one more team compete at the cost of the entire enterprise being mind numbingly annoying for the entire field is no good. The NDT is a case in point. People treated the decision to go to Harrisonburg but debate online as remarkable. I did not think that. It seemed like an inevitable result of giving people the choice in a hybrid format. Next year the reason won’t be “I don’t want to debate in a mask” but it will be something else that makes the tournament devolve. Just eliminate the discretion. Find another way to accomodate people, cuz this ain’t it. 2. People don’t debate enough Top 5 teams this year averaged 75 debates. In 2012 they averaged 96 debates. After 8 NDT prelims a host of teams managed to get into the 30s for total rounds. No good. I debated 98 times my junior year, went 4-4 at the NDT and was still really bad. A big part of this was the shift from 8 to 6 prelims. Got to debate more or settle in for mediocrity. 3. Antitrust topic is good It’s good to explore new lit bases (economics). If you didn’t like going for the cap K that’s on you, it’s good. If you didn’t know how to answer the cap K that’s on you. If you couldn’t conceptualize how to bolster an affirmative to make antitrust key seem better against CP’s that was on you. But mainly forcing people to read shit they have no idea about is good and the debates were manageable enough. Dare I say good when two try hards debated one another. 4. Debate needs more content and hype In-person debate tournaments should be bigger deals. More schools. More events even. Tournament hosts have to prioritize media. Video and photos. When a tournament happens a lot of video of rounds should come out of that tournament. The weekdays after tournaments should have recap content. Debate can’t say it is a worthwhile activity to be doing on the one hand and then on the other everyone wishes no one outside a tournament watches any of the rounds. Debate badly needs hype content creators. Also if we can get some Twitter presence besides the whole fucking KU team, it couldn’t hurt. 5. Not enough new affirmatives at the NDT Wtf are we doing 6. NDT wiki practices I bitch about this every year, but the fact that the wiki from the NDT is the worst major of the year is so shitty. Tournament-sponsored scouting efforts are insufficient, but cannibalize the will for people to do what they normally doeven though the normal stuff is better! Automatic email chains are cool, but unnecessary if people don’t update the wiki, and actively harmful if it results in less rounds making it onto DebateDocs. Twitter account thing, cool in spirit, but irrelevant in execution. Invest the resources in doing something else to make the NDT cool (*cough* media *cough*). 7. Topicality The community really needs to rethink T vs. policy AFFs. This issue is something that a lot of folks smarter than me have touched on in years past (see: Seth Gannon), but now bears repeating. I’ll start by saying I’m not opposed to topicality – obviously – nor am I opposed to voting NEG on T vs. a policy AFF. I have gone for it as a debater, I’ve coached debaters to do it, and have voted for it. Topicality is good. If the topic is, say, antitrust, and the AFF stands up and says “the USFG should enact a carbon tax”, they should lose. I also want to make it clear that I’m talking about policy debates, not clash debates. When the AFF has a prescription for the federal government to take a specific policy action and that policy relates to the topic, there is a significant amount of NEG ground baked in that would not be otherwise. When NEG teams go for T against policy AFFs, they do so by appealing to the importance of limits and clash around specific topic nuances. They wax poetic about the importance of depth on a small number of key issues. They decry the AFF’s horrific avoidance of substantive clash, and frantically point to the many thousands of new AFFs that judges would surely invite if they didn’t break their keyboard alt+tab’ing over to Tabroom and vote NEG as quickly as humanely possible. Unfortunately, by going for T in a policy debate, you are avoiding that substantive clash entirely. You are sacrificing an opportunity for specific, topic-oriented debate on an important issue, and instead making everyone spend 2 and a half hours talking about generalized debate theory. Worse, when NEG teams realize they can win debates on T instead of having to deal with the much more challenging approach of saying something substantive, they will have a perverse incentive to do that whenever possible. Going for a DA and case is hard. Your 2nr needs to be able to decisively frame your impact as more pertinent than the AFF’s, predict exactly which 1ar DA arguments the AFF will hone in on in the 2ar, and answer all the advantages the AFF extended into the 1ar – despite the fact that the 2ar will likely only go for one. The 2ar gets to speak last and will have more time to talk about everything. So what should 2ns do? Really, there’s only two options – they can either work hard, practice, and perfect their craft, writing smart and innovative DAs/CPs and practicing on them and beating teams that can’t match their pace of research – OR, they can take the easy way out and go for T. It’s pretty easy to go for T. The 1ar has very little time to talk about everything else in the debate, and T is just one of the many things they have to spend their precious seconds covering. When you can talk for 6 whole minutes of the 2nr vs. maybe 1:30 of the 1ar, and you can tell the judges everything that’s coming is new, and when judges just need the NEG to have an interpretation that is a little bit more limiting than the AFF’s… why not go for T? This brings me to another issue: competing interpretations. They are bad. A scary large amount of “good” judges in high-level policy debates would vote NEG in the following scenario: the NEG goes for T and has an interpretation that limits AFFs to 5 areas. The AFF counter-interpretation says it should actually be 6 areas. The NEG spends a lot of time talking about limits are a linear impact, must be maximized, blah blah blah. Even though the AFF only adds a tiny sliver to the NEG research burden, people will vote NEG because the NEG’s interpretation is better. That’s silly. Now let’s say the same two teams debate each other at the next tournament, and the AFF team has a whole new affirmative case – maybe now they’re within the old NEG “5 areas” interpretation. But then they’d read this new AFF, and all the neg would have to do is read an interpretation that limited it to 4 areas – and yet again, the NEG wins, because competing interpretations. As long as judges vote for the competing interps model, the NEG will always move the goalposts to generate an interpretation marginally more limiting. This same line of reasoning makes me skeptical of the “must have offense” paradigm for T. Does anybody believe that AFF teams can’t beat bad DAs with terminal defense alone? Does anybody believe that NEG teams can’t make silly advantages completely go away with some good re-highlighting, smart analytics, and recent evidence saying the AFF’s internal links are wrong? Offense is not required to make the risk of DAs or AFF advantages zero – so why isn’t the same thing true for T? Because if it’s not – if AFF teams must win offense against the NEG’s interpretation to ever have a chance of winning the debate – we’re going to see a lot more NEG teams going for T in debates where they could have gone for substance, a lot more judges voting NEG and saying some buzzwords like “only a risk” AROUND(10) “limits”, and creativity in the AFF-writing process completely snuffed out. The last thing I’ll say is that in most debates where the NEG goes for T, they are not actually without a substantive option. They likely have some generic topic DAs that apply, a counterplan that could capture a lot of the case, or even just the politics DA and “your AFF is wrong”. All of those are infinitely better than a pedantic T debate – even if the NEG doesn’t have hyper-specific link evidence about the AFF. I would greatly prefer the NEG to read more general DA link cards and then explain, through smart analytics, why they apply to the AFF’s specific mechanism than jettison the opportunity to debate substance entirely. Unfortunately, I think most teams that go for T do it because it’s easy and because debating the substance is hard. And as a lifelong 2n, I can say this: if you frequently find yourself without any credible NEG options, it’s not because the AFFs are too tricky – you just need to cut more cards. So, what should be done? Again, I’m obviously not for completely doing away with T in policy debates. It is important and unfortunately it’s often necessary – but I think that judges should seriously raise their threshold for voting on it. Specifically, I propose that judges treat voting NEG on T like they treat voting AFF on conditionality bad. Nobody wants to do the latter – it’s widely regarded as a cheap shot that should only justify an AFF ballot in the most egregious of circumstances. That said, if the “competing interpretations” model was applied to conditionality like it was applied to T, I promise you that judges would hear a lot less 2ars about the topic and a lot more 2ars about the pain of strategy skew. Within the few times in recent years that 2ars in notable debates have been about conditionality, many judges have included something like this in their decision: “yeah I mean… you were probably ahead on a lot… but you’re asking me to decide the result of the debate over it, and I just don’t think what the NEG did was that bad”. And that’s good! But there really isn’t a compelling reason why you can judge a conditionality debate that way and not do the same thing when the AFF says “we’re reasonable” and “they had ground” and “our AFF isn’t that hard to prepare against”. Those arguments – reasonability, substance crowd-out bad, and appeals to automatic NEG ground/functional limits – should be enough unless the AFF is totally out of bounds. When you ask me to vote NEG on T, you’re saying that the AFF is so heinously untopical that they should lose a debate over it. Sometimes that’s the case – but I think most of the time in policy debates, it’s not. I think that if judges collectively raised their threshold for voting on T, we’d consequently see more and better substantive debates across the board. 8. People reading the same aff all year Ass. Zero. Grow up. 9. Conditionality Two observations. First, conditionality has seemed to ebb and flow in popularity over the last several years. We appear to be on the upswing, with several important elim and round robin debates decided on conditionality this year, as AFFs decided the antitrust NEG box was too scary. Second, Emory won a debate on conditionality when breaking a new AFF, and people seemed shocked – it was supposed to be unwinnable when breaking new! Both of these are ass. Neither the moral panics nor the arbitrary immunity from theoretical objections for NEG vs new AFF teams are grounded in any principled justification. The best NEG arguments for conditionality, such as logic, are not affected by an undisclosed new AFF. Arguments like ground might change slightly. However, if you think new AFFs hurt NEG ground enough to justify NEG terrorism, you just think new undisclosed AFFs are bad. If, on the other hand, you think NEGs should prep for new AFF scenarios and that solves abuse from nondisclosure, your evaluation of conditionality shouldn’t be impacted by non-disclosure either. 10. Thumpers I asked someone for a hot take and they just started yelling all caps “FUCK THUMPERS.” The argument being (which I find a lot more in high school, but maybe it has spilled up to college) is that affirmatives are very poor at answering DA’s because they rely on link uniqueness for everything. It definitely trades off with affirmative specific answers to things and the affirmative pursuing offensive strategies against DA’s. I wasn’t locked in enough this year to comment on how rampant this was, but it has to be said to 2A’s – there are better arguments out there then link uniqueness. 11. Textual Competition It reared its ugly head once again at this NDT and caught some people off guard. Let’s recap some of its issues. Competition is supposed to help the judge figure out if the NEG has negated. Standards like ‘textual competition’ or ‘functional competition’ are tools that we can use to help answer that question. When these tools are producing answers clearly at odds with our intuition about whether the NEG has negated, that is a good sign that the tools might be due for a reexamination. Imagine the AFF proposes restricting pollution of a lake in Minnesota, and the NEG responds by saying water consumption in Florida should be unlimited. Clearly the NEG has not negated the proposal – there is no link to the DA. This remains the case when the NEG adds a uniqueness CP to abolish restrictions on water consumption in Florida – doing both clearly solves any advantage to the CP – and even when the NEG adds a plank to ‘ban the plan’ – the AFF can simply permute the other planks. But all of a sudden, the NEG has a clever idea, and abolishes ALL water protection. Perm do both no longer works – the plan and CP are mutually exclusive. However, we are meant to believe that “perm – do the plan and abolish water protection in Florida” ALSO fails, because neither the plan nor CP contains an abolition whose bounds are specified, and neither the CP nor plan includes the word Florida. This despite the ‘DA’ component of the strategy remaining totally unchanged, and continuing to obviously not link to the plan. This despite the ‘CP’ only differing from the above ‘ban the plan’ example by banning the plan in one clause, instead of two. Clearly, none of this changes whether the NEG has negated. It is an irrelevant language game. Luckily, there is a simple solution for the AFF – replace “increase protection of Minnesota lakes from overuse” with “increase restrictions barring overusing of Minnesota lakes.” That opens the door for “perm – abolish water protection, barring restricting overuse of MN lakes.” Oh, you don’t like that the word “barring” changed meaning between the sentences? Too bad – you brought this on yourself by claiming ‘abolish in Florida’ is not a subset of ‘abolish everywhere.’ Welcome to textual competition clown land. The intent was good – people had an intuition that seemingly functionally competitive strategies, such as the consult CP, were winning debates, despite intuitively not negating the plan. Textual competition was a poor solution then, and it’s a poor solution now, as it is deployed for the exact opposite purpose – the equivalent of running back the world government CP that bit the dust to a Roger Solt article in the 1980s. 12. Darty heg If only we allowed widespread betting on the NDT we could have seen what the price on the Darty repeat was. Gotta say pretty medium sized underdogs given the fact the first final they made was the NDT itself! For those that don’t know: James Q. Wilson & Holt Spicer – Redlands -50’s William Welsh & Richard Kirshberg – Northwestern – 50’s Sean McCaffity & Jody Terry – Northwestern -94/95 Michael Gottlieb & Ryan Sparacino – Northwestern – 98/99 Tristan Morales – Northwestern – 2003/2005 Andrew Arsht & Andrew Markoff – Georgetown – 2012/2014 Tyler Vergho – Dartmouth – 2021/2022 That is the list of people who won the NDT more than once I believe. No one has won the NDT three times (yet…). Tyler is also the first to win the NDT two years in a row with two different partners. This year, he repeated his accomplishment while having COVID. In doing so they surpassed Harvard’s total win count, with 8 lifetime wins to Harvard’s 7. None of this is to obscure Turner’s well-deserved coach of the year award. Incredible. I am ready and willing to embrace the new Darty overlords. But we should stop and think what Turner is going to do for an encore. Win the NDT only cutting 10 cards? Win on the coercion DA? Win with two novices? Hard to say what a man so drunk with power and accomplishment is willing to do. 13. Honorable Mentions I was not particularly dialed into the season, but wanted to give some shout outs. The qualifications for being on this list were doing something cool that I or someone else who brought something to my attention noticed. People probably did cool stuff that I did not notice. This does not mean it was less cool, only that it didn’t get on my radar. In no particular order:
Good job persevering another year. Less persevering and more thriving in 2022-2023. My first realistic job plan was when I was 17 and it was to become a professional poker player. Then my brother intervened and told me to go to college and do debate. Then I was going to be a math teacher and high school debate coach, but the math proved too hard and cutting cards too fun. I did some fact finding if you could be a full time debate coach and avoid homelessness. It turns out the answer was yes, so we were in. I would give my personal debate results a C+. That really masks how bad I was and how little I knew. I graduated and worked at Liberty. My clearest first memory of coaching was when I went to cut a file for the first time and it just did not fire. “oh I do this for other people and not myself anymore?” “oh I don’t get to use this?” “I don’t get to have judges vote for me anymore” “yo, this shit is kind of tedious” “we have to cut cards about WHAT?” For a little while there I landed on I will just find the articles and have my minions cut them. Easy. Going into that GSU our tub was pretty shitty, but we kind of knew what an SMR was so were doing better than others, but worse than most. After GSU that year the light switch went on. All I wanted to do was crush opponents. I did want cards about everything. If someone broke an argument I didn’t predict, it made me mad. If someone broke an argument I wrote before we did, it made me mad. If someone found an article I had not seen before, it made me mad and I wondered how the hell did this person find this card. I was high on spiteful motivation, but that didn’t necessarily translate into improving at my craft to the same degree. I cut so many bad cards for so long, I am thankful I have lost access to most of them so I cannot open the documents and cringe at the dogshit formatting and the inept argument I was making. I had a choice to make after my first year coaching. Option 1 - go to Georgetown, be a contractor, don’t make a lot of money, live in a shoebox with 4 other dudes but join a juggernaut of a team. Option 2 – go to Kentucky, join a team after their first year of a reboot, better pay/cost of living situation. 2013-2019: We built a team. People’s hard work drove each other to get better. People improved their craft. Classes of debaters passed down lessons learned, traditions and tips in debauchery. I made my best friends who I talk to everyday. We banded together to do tasks none of us really wanted to do. We culminated it in winning a national championship. This has been like a judge who starts the post round with saying a bunch of shit without how they voted. My punchline: I am resigning from the University of Kentucky. I have been in a haze the last three seasons. Me as a coach has not been the same the last 3 topics compared to the 7 that came before it. It is one of two things. Either I am washed and I cannot do this activity the way I want to do it OR my external circumstances are preventing me from doing it. My job at UK has transformed the last 3 seasons into a host of external circumstances. I won’t bore you with the laundry list. No job is free of tasks you would rather not do, but they wear you down after a while. At bottom, the issue is I do not like myself when I am associated with mediocrity. I have been a mediocre debate coach the last three seasons. I have done some other stuff, like tournament hosting, pretty well in that time. But that isn’t going to last. Too many different kinds of tasks, too many hats, too much complexity, too much stuff that isn’t what I want to do means those things are going to be mediocre too. So my solution was to remove myself from the situation. I couldn’t make Kentucky an everlasting debate dynasty. I couldn’t make the TOC what it should be (a full time job tbh). I didn’t help start any new college debate programs. I didn’t help fix what ails college debate. I don’t have a satisfying list of reasons why that is the case, but the proof is in the pudding. I wish all the troopers in full time college debate the best of luck. I am not quitting the activity for good, I will be around. Hopefully, being less immersed in the totality of a college debate team will help me both find roles I can excel at and enjoy and be more helpful in targeted ways than I have been. Posted this to the debatedocs group. Hoping for more and better participation going forward!
Hi all, The basic bargain of this group was that if you were willing to proactively send your email threads to this group you got the benefit of all the other members doing the same. In theory, this would reduce/eliminate the need to bounce from room to room (or Zoom to Zoom) to ask to get on email chains. A few issues: 1. Free riders - mainly coaches who are in the group but require nothing of their teams. 2. Side bias - people do it when they are aff and create a chain, but do it much less often when they are negative. 3. Some teams but not all teams - another coach one, the idea was a coach could require all their teams to participate increasing the overall utility of the group. In practice a squad's participation when their coach jumps in the group has been sporadic. Here is my game plan First, purge all the members of this group Second, people can rejoin by emailing me at [email protected] Third, I will do a better job of tracking who the active participants of the group are and I will share that with everyone. Fourth, come the end of this semester (post Wake) I will look to see how well participants shared with the group. If you suck, you get the boot. I considered starting a new group but I like the debatedocs name and it is a habit for some. Also someone will come along and data mine this group and resell it to high schoolers and I don't want to deny them that opportunity. So goodbye for now, but hopefully see you back in here soon. Thanks, Lincoln By: The Writers of the Climate Area Paper
We appreciate the hard work of every topic writer, and all the effort each paper put in. This post is a defense of the climate topic from the recent guest post’s arguments, which we find to be ill-founded. The core premise of the earlier post assumes the climate paper was written and endorsed by coaches looking for a quick paycheck. This paper was the only paper written by an overwhelming number of current policy debaters. The conversation includes the opinions of current students and the hard work of debaters from dozens of different programs. The broad agreement amongst students is we want to talk about climate change. Debaters receive a limited number of years to debate the subjects they find interesting, and current students have lost many emblems of a college career to COVID restrictions. Prioritizing the likes of coaches who have an infinite number of topics and tournaments ahead of them fails students. Climate change debates are educational, interesting to research, and something this generation of debaters wants the opportunity to debate. As for the two main assertions in this blog: A. File Recycling and Laziness:
Perhaps courage is less so an anonymous fear-mongering blog post, and rather an expression of interest in learning about climate change from students across a diverse number of districts and ideological styles of debate. By Anonymous
As we near the time to choose a college topic again this year, I humbly approach readers of the blog with an earnest plea: don’t pick the climate topic. Off the bat, I want to make clear that I’m mostly talking to coaches and older folks, not the actual debaters per se, as most of these discussions unfortunately are dominated by the former and don’t include too much inclusion of the latter’s perspective. I’m also mostly talking about policy debates as opposed to K debates. Anyways, here we go… First and most significantly, picking the climate topic will encourage laziness in research. For those living under a rock, we just had a climate topic in 2016-2017. A whole year’s worth of debates was just had on this issue only 4 years ago. I wish I could say that people will work hard to develop new ideas and original research on this topic, but truly, anyone who says that will happen is not being honest with themselves about quality and quantity of research this past couple years. There’s an unfortunate reality when it comes to doing debate research: most people will work only as hard as you require them to, and no harder. If climate is our topic, the first move for most of the card-cutters in our community will be to go back to the 2017 Dropbox and copy+paste large quantities of args. Sure, some files will require some updates, but the important part – actually coming up with ideas for affs, DAs, and CPs, and cutting a critical mass of cards about them – is done. Coaches will throw a couple 2021 uniqueness cards into a DA file, maybe change some formatting, and voila – a whole file is done! They’ll send their teams the files, bask in the compliments about how quickly they’ve done all this preseason work, collect their check, and be entirely insulated from the adverse consequences it has on the community. Don’t believe me when I say that people will be as lazy as you allow them to be? Look at how many times Fisher 15 was read as a 1ac impact card last year in NATO 1acs! That card is AWFUL, and it was everywhere! Instead of taking 5 minutes and cutting a new 2020 US-Russia war impact card (of which there are literal thousands), people just went back to college wikis of old – because it was the easy thing to do. I don’t even really blame them – debate work is a pretty thankless task, and most coaches are not paid very well for their work. If I’m a 28-year-old card cutter, I have other things to do, and I’m getting paid either way, why WOULDN’T I just copy+paste from the old wiki/Dropbox? In fact, it’s the rational thing to do! Here’s the problem, though – decline in quality and quantity of research is a large contributing factor to the decline in quality of debates. When coaches decide that they only have to do the bare minimum for research, it sets the same example for students under them. If you’re not willing to put in the work to develop sound original argument ideas with recent and qualified evidence, how could you possibly ask your debaters to do the same? This dynamic creates a race to the bottom (for lack of a better phrase) that has follow-on effects in the actual quality of debates as well. Given this, we need corrective action. The most effective way to encourage someone to research something new is to ensure that they don’t have the option of credibly copy-pasting old work. Let’s say we picked income inequality, anti-trust, or even labor. How many cards are there circulating about those topics in debate right now? Probably less than 100. Pick one of those topics, make the community debate about it, and card-cutters will have no choice but to do original research. If you’re an argument coach, your job should be to do this anyway. Do your job. Secondly, the college debate community is experiencing a pretty serious patch of stagnation when it comes to actually learning about new ideas. We’ve decided that there’s a set of topics that we’re interested in and will debate ad nauseum, and that there’s other topics that appear “boring” on the surface and thus won’t be touched by a 10-foot research pole. Don’t get me wrong, climate policy is an interesting area, and there’s a lot to learn from studying it. However, it’s an area that the community already has a relatively high level of knowledge about. Even when it comes to young current debaters who never debated the climate topic, most know something about climate policy, climate change, and the various energy industry DAs. That stuff comes up on every topic. You know what literally never comes up in debates? Anti-trust law. If you polled a random sample of debaters and coaches, I would estimate that less than 50% could even give you a working definition of what “anti-trust law” means. The same is true (to slightly varying extents) when it comes to income inequality, labor, AI regulation, etc. These are all staggeringly important areas of public policy that will shape a lot of our lives in the coming decades. Why doesn’t anyone want to research them? The purpose of debate is at least ostensibly to learn a lot about different areas of public interest. We haven’t been too good at picking “different” areas as of late – hell, we just did military topic redux, even though the community recently debated that one too! It's good to learn new things and explore new areas of research. This should be uncontroversial. Unfortunately, many powerful figures in our community seem to want us to debate the same stale topics over and over again because it makes their jobs easier. As a community, let’s have some moral courage and try something new. Apologies friends, the TOC is a hell of a drug. We have 8 submissions from people who like fun. We are going to do this rank choiced voting style. Let's see who wins clout and glory!
By Anthony Trufanov In 1991, T.A. McKinney, an accomplished Kentucky Wildcat of an earlier generation, wrote an essay for the Wake Forest Debater’s Research Guide entitled “Rehabilitating Intrinsicness,” which laid out the case for holding disadvantages to a higher standard of causality[1]. The essay has aged like fine wine; while debate has shifted in many meaningful respects, McKinney’s paper remains well-argued and relevant to this day. Nevertheless, the article largely failed in its goal of popularizing intrinsicness. The state of affairs McKinney described in his introduction—of “widespread hostility to intrinsicness on the part of judges,” or of “weak-kneed affirmative teams who abandon ship in the face of four or five meekly mumbled negative objections”—persists to this day. This response is too often reactionary, grounded in received wisdom from coaches or peers who are themselves several generations removed from the last time the concept received a fair hearing. This follow-up is my attempt to pick up McKinney’s project where he left it: to rehabilitate the idea of intrinsicness, or the “minor repair,” in a form that could be suitable to debate in 2021. My primary argument is that reasonable and beneficial intrinsicness arguments founder when presented in debates due to debaters’ inability to articulate a principled distinction between permissible and impermissible “minor repairs.” As a result, debaters are throwing the baby out with the bathwater. A methodology for parsing good intrinsicness tests from bad is needed. Fortunately, we need not look far for a viable approach. After all, debaters and judges, collectively, have decades of experience debating the legitimate boundaries of non-resolutional fiat when the negative introduces it! Instead of inventing a taxonomy of intrinsicness tests out of whole cloth, I propose an adaptation of counterplan theory to limit the power of the AFF to articulate minor repairs. Under this framework:
Defining Intrinsicness Before getting into our discussion, we must define our terms. At the most basic level, intrinsicness asks the question: in evaluating the plan’s merits, which consequences are relevant to consider? There are several ways to approach this discussion. Merriam-Webster defines intrinsicness as “belonging to the essential nature or constitution of a thing”[3]; in other words, it is “the intuitive idea that a property is intrinsic roughly if it is necessary to a thing being what it is”[4]. At face value, this idea would seem to invite an age-old ethical debate concerning the difference between an act’s inherent properties and its consequences, and an even older phenomenological discussion about whether it is possible to ascertain the essence of things, or whether such an essence exists in the first place. Staying true to this common usage might lead us to conclude that intrinsicness theory gestures to similar ideas to any framing contention about deontology and causality, which might be found in hundreds of popular high school 1ACs. Such a line of argument might claim that the goodness or badness of an act inheres from its intrinsic qualities rather than from its indirect results. However, this is not what AFF debaters usually say today when they bring up intrinsicness in a 2AC. Instead, AFF debaters invoke intrinsicness as a proxy for a different notion: that there should be a uniform standard for causality, applied reciprocally to AFF and NEG teams. More specifically, they argue that for consequence y to be considered a salient cost or benefit of plan x, the presence of x must be both a sufficient and necessary condition for the presence of y:
Benefits of the Intrinsicness Standard—Reciprocity Having clarified the terms of the discussion, let’s delve into why such a change is needed. There are three compelling justifications for restoring the core elements of the intrinsicness standard. The first justification for restoring an intrinsicness standard is consistency and AFF/NEG reciprocity. The problem is straightforward: the relevance of causal relationships should not be contingent on which team brings them up. To see why, let’s return to the agenda trade-off DA. Isn’t it quite strange that the saliency of the plan’s popularity and its effect on presidential political capital varies so dramatically by side? When introduced by the NEG, such an argument typically draws multiple minutes of 2AC refutation. However, when submitted by the AFF, such an argument would draw nothing but a chuckle and a one-sentence counterplan text. While AFF and NEG debating differs in many ways, one would think that fundamental causality, at least, would remain relatively constant. Zooming out, we find an even more confusing picture. Intrinsicness is already pervasive in policy debates, albeit concealed under different names. Few would be especially troubled by a court AFF that did not specify its agent in the plan text making an agent-based no link argument against an agenda crowd-out politics DA, even though such an argument could just as easily be rephrased as “not intrinsic: not all worlds which contain plan x contain DA y, because some worlds containing x use a judicial actor.” Hardly any would object to an AFF team utilizing a basic “permutation: do both” argument to argue that a CP solves the link to a DA, even though such an argument could be rewritten as “not intrinsic: not all worlds which contain plan x contain DA y, because worlds containing both x and CP z do not contain y.” The current standard for causality in debate, then, is more a confusing and nonsensical patchwork than a logical framework for cost-benefit analysis:
Benefits of the Intrinsicness Standard—Real World The second justification for restoring an intrinsicness standard is that it is real world. Simply put, decision-makers frequently invoke intrinsicness standards as a reason for dismissing objections to proposals for change, ranging from policy discussions to more mundane decisions in our day-to-day. It would surely be unreasonable to reject the option of going outside during winter because it is cold without having even considered the option to put on a coat. McKinney’s article on intrinsicness provides another real-world example, in which a CIA lecturer rejects the “Soviet economic collapse” disadvantage to cracking down on Soviet IP theft because economic risk can be solved through aid[5]. Many more examples could be offered, but even these few should suffice to illustrate the pervasiveness of the intrinsicness standard in the evaluation of real-world disadvantages. Benefits of the Intrinsicness Standard—Quality of Clash The final justification for restoring an intrinsicness standard for NEG arguments is the quality of clash. Clash occurs when two sides disagree with each other. This is the essence of debate—two sides argue about an issue, exchange evidence and ideas, and, in the process, hopefully come to an improved understanding. There are many schools of thought on what constitutes high-quality clash. However, one reasonable way to discern good clash from bad is to compare the objections raised by NEG teams to those raised by the NEG literature base. Put another way—would a topic area expert crafting a 1NC arrive at a similar set of themes as the NEG team? If debate purports to carry educational value, one should expect there to be some resemblance between policy debates and real-world debates about policies between experts familiar with the critical points of clash on an issue. While it is difficult to demonstrate this in any rigorous or scientific way, I believe policy NEG teams are, broadly speaking, falling well short of this metric. A peek under the hood of most high school teams’ file collections over the last few years would reveal precious few disadvantage arguments at all, to say nothing of disadvantages with intrinsic links. Even fewer teams can claim to have a file unrelated to politics—midterms, agenda, rider, and horse-trading arguments likely accounted for a significant portion, if not a majority, of disadvantage arguments introduced in a 1NC in recent years. To check this intuition, I surveyed the 2NR strategies of the teams ranked top 25 on the Coaches’ Poll against policy affirmatives. I chose this sample because teams in the top 25 are more likely to maintain good disclosure practices and because teams in the top 25 likely have the most effective preparation practices. I excluded rounds in which the 2NR was not specified in the round report and did not investigate rounds where disclosure was missing. The results essentially confirmed my suspicions[6]. Excluding teams that usually go for kritiks, 20% of arguments appearing in policy or “flex” teams’ 2NRs were some flavor of politics DA. Politics arguments were almost four times as common as broad topic arguments like the federalism DA, the crime DA, or the separation of powers DA, and four times as common as specific DAs about the affirmative being debated. While politics DAs were sometimes coupled with specific CPs about the affirmative (usually advantage CPs), it was far more common to see politics accompanied by an agent CP strategy, commonly with zero specific evidence. None of this is an accident. Instead, politics has become a stand-in that teams rely on to replace actual research about the topic. To be clear, there is no judgment for debaters who do this. By my count, teams attending the policy TOC in 2021 had read, between them, about 80 different categories of AFFs (each “category” defined as a grouping of AFFs for which specific NEG research would not generally overlap), to say nothing of new AFFs presented at the actual tournament. The impulse to relieve the burden by abandoning the pursuit of specific NEG strategies is entirely understandable. Individual teams or debaters who internalize all of the costs of the extra work but do not internalize all of the benefits of higher quality debates are unlikely to abandon this calculus without being compelled to do so by the forward march of debate theory. Reading a paragraph like that would probably make any serious NEG researcher shudder. Am I really suggesting that NEGs should be deprived of their most popular tools for managing complexity on a topic where even the most industrious NEG researchers could not keep up? Who, other than an unhinged 2A with no concern for the free time of embattled 2Ns nationwide, would write something like that? I admit, this is the objection to intrinsicness that I found the most persuasive at first. Upon closer inspection, however, even this objection falters. First, this is not actually an objection to intrinsicness; it is an objection to broad topics! NEG teams had no trouble crafting intrinsic objections to establishing National Health Insurance, describing the economic harms of a national Cap-and-Trade scheme, or illustrating the damage a no-first-use policy would do to nuclear deterrence. Many students who participated in high-level debates on these issues remember those rounds fondly for their depth, detail, and intellectual stimulation. Good topics—those with narrow and balanced ground—enable plenty of engagement even without the padding offered by non-intrinsic objections. “Be that as it may,” you might be thinking, “but the flawed topic process, especially in high school, cannot produce resolutions like this consistently.” That is not the right way to approach the issue. As a famous legal axiom reminds us, “hard cases make bad law.” Considering the most recent high school topics, the temptation to prioritize NEG ground above everything else is understandably strong. But lowering the bar for what counts as a relevant NEG link argument is a poor solution. It does not create “good” policy debates; it simply raises the tolerance for non-sequiturs from NEG teams. Conceding that intrinsicness would be more logical but rejecting it for the sake of debatability would justify any other distortions to help the NEG. Why not arbitrarily reduce the importance of uniqueness for NEG arguments, as in public forum, just to make it easier to negate? This illusion of balance is not free—it comes at the cost of coherent, logical argumentation on topics that would have supported it, in the rare cases when they come up. It is a travesty that any debates on the national health insurance topic were decided by the rider DA. Even worse, forgoing intrinsicness does broader damage by masking the imbalanced and poorly calibrated nature of high school topics through nonsensical 1NC padding that would never withstand scrutiny in a serious discussion. This steam valve lessens pressure for the only real solution: greater discipline by the topic committee in choosing limiting language for AFF teams. Fortunately, teams do not have to wait for the topic committee to dramatically improve before making intrinsicness a mainstream expectation for the NEG. Instead, debaters can use topicality as a dynamic tool to adjust the scope of topics until it is in line with the updated division of NEG ground. The best topicality debaters go into considerable detail concerning their vision for what debates on the topic should look like. If an intrinsicness standard is introduced, these debaters will point to the rising bar for NEG arguments to make their case for limiting interpretations more compelling. This can even occur on “poorly written” topics, since debatability can outweigh precision or predictability when the stakes are sufficiently dire. In some ways, such topicality arguments distort the “reality” of debates about a topic much in the same way as non-intrinsic disadvantages. But distorting a topic is a better solution than distorting the role of the NEG. Topics change every year, but the role of the NEG is forever. I recognize that implementing a stricter intrinsicness standard in a way that “syncs up” with a higher quality topic would not be easy. However, the inability to attain buy-in for a vision of debate has never been a valid reason to reject a theory interpretation. The implementation question is far from trivial, of course. However, for the purposes of this paper, if the sequencing issue is your only remaining objection and you agree that the vision of debate I am describing would be superior to the status quo, consider yourself convinced. Second, concerns about NEG ground are overblown. Teams are already finding ways to limit their reliance on non-intrinsic disadvantages, even if not intentionally, simply because non-intrinsic objections are often weaker. Looking back to our 2NR breakdown from earlier, we can see a variety of positions that could survive an intrinsicness objection: elections DAs, court legitimacy DAs, topic generics like the crime DA or federalism DA, impact turns, kritiks, and topicality arguments accounted for 60% of arguments that appeared in 2NRs! Minneapolis South, the team ranked #1, was a model in this respect. They are the only team that went for case-specific offense more often than they went for the politics DA. Most of their 2NRs contained a topicality argument or kritik. Current 2NR breakdown data is an imperfect indicator, however. The historical record shows that NEGs find a way; it is not as if NEG researchers would roll over and give up in response to a demand for more specificity. Perhaps more case NEGs and case-specific strategies would be written. Perhaps researchers would make more intentional efforts to approach that ever-elusive goal of applying core NEG themes to specific examples. Perhaps people would delve into the literature instead of accelerating the casual mockery of the separation of powers that traditionally occurs in agent CP texts. I do not know the optimal percentage of case-specific DA and CP 2NRs as a share of all 2NR positions, but it is surely greater than 8%. Minor prep adjustments can also rescue many arguments from the intrinsicness dustbin. NEG teams should simply prep disadvantages or other responses to the minor repair! Imagine you have a court precedent DA, arguing that the plan’s ruling spills over to other areas, which would result in something bad. Much like a court precedent ADV, your DA would have to reckon with the “distinguish” test—why not make the plan’s ruling, and distinguish the precedent DA’s impact? An AFF reading a precedent advantage must make additional arguments about why consistent and coherent precedent is beneficial—whether for business confidence, for clarity of law, or for any other reason. A NEG team reading a DA could easily say something similar. Thinking about intrinsicness arguments as a mirror image of CPs provides a helpful way of thinking about this issue. Remember—AFF teams are already held to this standard, and few would argue that CPs should be banned because the threshold they create is too burdensome. This is partly because the solvency of counterplans and intrinsicness tests is not a binary proposition; CPs can solve some of a case, and intrinsicness tests solve some of a DA link. Consider a relations ADV or DA. Just as AFFs can respond to relations ADV CPs by explaining why the plan is a vital issue in the relationship, NEGs can respond to relations intrinsicness tests by explaining that the plan still does significant net damage. This move would refocus the debate on what is really at issue: whether the plan is an element of the best policy option and whether the addition of the plan creates a net cost or a net benefit. Having summarized the benefits of intrinsicness, let us go through some common, and some not so common, objections. Responding to Objections—“AFF Fiat Power is Limited to the Resolution” Many common objections to intrinsicness—including this one—rest on the belief that an intrinsicness test is an advocacy, or becomes a component of the AFF’s broader advocacy, or requires AFF fiat to implement. This is incorrect. Remember—intrinsicness tests merely say that NEG’s offensive argument is not relevant because it is easy to remedy without forgoing the plan and its benefits. This does not mean voting AFF causes the intrinsicness test to happen and does not mean the intrinsicness test becomes part of the AFF’s proposal; it only means that certain downsides to the plan are ruled out from consideration because they would be easy to fix if the plan were enacted. A disadvantage to the intrinsicness test would not be a reason to reject the plan, only a reason that the repair proposed for the original disadvantage would not be viable. Similarly, advantages to the intrinsicness test are not reasons the plan is good. A close analogy is an AFF permutation, which also solves NEG offense, but cannot produce AFF offense, and whose undesirability cannot, by itself, serve as a reason to reject the plan. A related set of objections also fails for this reason. Intrinsicness is not a “moving target”—nothing is “moving” because the core advocacy remains static, and addenda are closer to “no link” arguments than to advocacies. Intrinsicness is also not argumentatively irresponsible since the AFF is not jettisoning any part of its original proposal. While the AFF does get to discard intrinsicness tests at will, this is reciprocal to conditionality on the NEG. It is also no different than not extending “no link” arguments on the AFF or not extending a permutation. Even if one is not convinced by this distinction, the form of fiat ostensibly being used by an intrinsicness test is entirely unobjectionable. The view that the judge’s fiat power comes exclusively from the resolution is outdated; how else do we explain NEG CPs, AFF perms, K ALTs, and K AFFs? Fiat is nothing more than the intellectual practice of imagining a different world for the instrumental purpose of determining whether the AFF is net beneficial or net costly. For reasons explained above, intrinsicness serves this purpose by helping parse relevant consequences from irrelevant ones. Lastly, even if this argument is correct, it is not a reason to reject intrinsicness categorically, only a reason to reject non-topical intrinsicness. Topical intrinsicness tests, helping teams deal with arguments like the sentencing horse-trading DA or the incremental reform trades off with comprehensive reform DA, should still be permissible since the fiat used by the remedy originates from the topic. Responding to Objections—“Non-Reciprocity is Justified by the Inherency Burden” This argument comes from a profoundly anachronistic conception of the AFF inherency burden. Per this argument, the inherency burden requires the AFF team to prove that harms being described are inherent (or intrinsic) to the status quo policy—in other words, that harms “inhere” to the status quo, creating an “inherent and compelling need” for change. This phrasing of the inherency burden is an old chestnut, invoked in stock issues debates as early as 1965 by Paul Newman[7]. However, even Newman’s contemporaries called such conceptions of inherency into question, instead describing inherency as requiring AFF teams to prove that something “other than a mere quantitative change in the current way of doing things… is needed to solve the problem”[8]. The latter definition, requiring “other than quantitative” change, does not, by itself, suggest that AFF harms must persist irrespective of all conceivable non-plan adjustments before they can be considered relevant. This should be obvious since inherency considerably predates the popularization of the CP. Even if Newman’s description were correct, however, it would not justify differential treatment of AFF and NEG link arguments for two reasons. First, even the most strictly interpreted inherency burden would not justify lowering the standard for NEG arguments. Inherency might require the AFF to prove its harms inhere to the non-plan, but this, by itself, says nothing (beyond serving as one basis for presumption) about what is required of the NEG. Second, a tenuous connection to one of the burdens of proof does not outweigh the overwhelming pedagogical advantages of forcing the NEG to engage with a higher level of specificity. Inherency is not a suicide pact; the stock issues should evolve to match the demands of the times. There is precedent for such changes. After all, few hold AFF teams to the standards set out by attitudinal, structural, or philosophical inherency. To the extent that the inherency burden cuts against requiring NEG link arguments to be intrinsic, it is the inherency burden, rather than the intrinsicness requirement, that should give way. Responding to Objections—“The Judge is a Single Policymaker, And Therefore Cannot Count On The Passage of the Remedy” This argument is puzzling. Why would the judge be a single policymaker or Congressperson? There is no basis in the topic or the AFF or NEG burdens for such a judge role. Moreover, this interpretation is belied by practices that contemporary debate takes for granted. Non-policy advocacies that could not be endorsed by a member of Congress, or agent CPs that compare the efficacy of Congressional action to action by the executive branch, the courts, or even the states, could not be logically evaluated by a single policymaker. Moreover, if the judge is a single policymaker, it is unclear why they should be empowered to implement the plan in the first place. There are, after all, few things that any individual within the government can accomplish through fiat. AFF teams frequently misstep when answering this argument, forgoing the opportunity to point out the arbitrariness of this interpretation in order to argue that the judge is, in fact, the entire United States federal government. Aside from being equally arbitrary, this interpretation has the added downside of being incoherent. What does it even mean for the judge to “be” the United States federal government? It is much simpler to abandon the charade that judges are “role-playing” as anyone or anything and treat judges as what they are: human educators whose job is to determine the winner of a debate round by endorsing a normative statement. So conceived, judge fiat power does not derive from anywhere; fiat is simply the imagination of change, and judges can vote for CPs, ALTs, and perms because the imagination of change is a simple human capacity with which they are endowed. Judges are therefore perfectly capable of voting AFF and giving an RFD that sounds something like: “the plan would be net beneficial because cost y would be easy to address through repair z.” Responding to Objections—“The Judge’s Role Alternates Between a Policymaker Constrained By The Topic and an Unconstrained Policymaker Depending on Which Direction They Vote” This interpretation is more subtle and superficially less arbitrary since it purports to originate in the topic. However, this interpretation, too, fails. First, its justifications are specious. Either this interpretation relies on the notion that intrinsicness is circumscribed by the topic (an objection addressed above—intrinsicness neither uses fiat nor amends the plan, so it should not be topic-bound), or it arbitrarily limits the cognitive powers of the judge in the interests of fairness (an interest better served by limiting the topic). Second, this interpretation is still arbitrary and divorced from reality. It still does not account for the presence of kritiks or non-resolutional AFFs. It is also inaccurate since the judge’s power to decide between normative statements is, as a descriptive matter, not limited; they may support any proposal they wish to support. Responding to Objections—“Non-Reciprocity is Justified by the AFF’s Choice of the Focus of the Debate & Infinite Prep” At root, this is a NEG ground argument in disguise. The appropriate solution is to narrow the AFF’s choice of debate focus through narrow topic-writing or topicality rather than lowering the bar for NEG link arguments. A variation on this argument concerning the AFF’s infinite prep is slightly more threatening. Unlimited prep does justify, to some degree, the differential in standards for each side; after all, the AFF should theoretically come up with the perfect proposal and should not require “minor repairs.” There are two problems with this justification. First, the imperfections at issue are not the result of shoddy prep. Instead, they result from topical constraints that prevent the AFF from specifying their solutions for the plan’s adverse effects in advance. It is therefore inappropriate to punish the AFF for imperfections in their proposals. Second, this presumes that an intrinsicness test amends the AFF’s proposal to eliminate a defect. For reasons explained above, this is not the case. At a minimum, shouldn’t the ability to choose the perfect topical proposal rule out topical intrinsicness remedies? No. First, it would be bizarre and unintuitive to allow the AFF non-topical remedies while barring topical ones. Second, this assumes, once again, that the remedy modifies the AFF’s proposal. The AFF did not add the topical remedy to their proposal because they are not proposing it; they are merely arguing that a judge could endorse an additional topical step if it furthered an end they wished to preserve through their vote. Taking a broader view, one might expand this genre of argument to include general questions of AFF and NEG parity. I will not venture into this discussion; it is a bottomless rabbit hole. All I will say is that it is unclear why such considerations, at their most abstract, should inform our understanding of causality. As with abstract notions of NEG ground, lowering the bar for NEG link arguments is a poorly-tailored and unnecessary solution when narrower remedies for side disparities, such as topicality, are available. Responding to Objections—“Teams Would Choose Egregious Intrinsicness Tests” The beauty of my proposal is that it provides a toolkit for NEG teams to argue against specific egregious intrinsicness tests without claiming that the intrinsicness standard is conceptually flawed. An intrinsicness test to do the AFF and have Russia not go to war with the US to solve a US-Russia war impact would be easy to dismiss by saying international intrinsicness tests are illegitimate. Using the possibility of a Russia-actor intrinsicness test as an argument against intrinsicness is no different than using the possibility of a Russia CP to argue that there should be no CPs. Just as good CPs can be distinguished from bad, bad tests can be dismissed while retaining good ones. Problematic uses of facially legitimate intrinsicness tests can be disputed as well. One common concern is that intrinsicness would be used to kick out of straight-turned ADVs. This is not a reason to jettison intrinsicness, only a reason to ban the practice of using intrinsicness tests to get out of straight turns. The practice is clearly bad—equally so when NEG teams do it to their own straight-turned DAs. There are two rationales to reject this behavior. First, the introduction of an ADV or DA carries the implication of a sufficient and necessary causal relationship, which the team that introduced the argument cannot “take back” after introducing it. Second, bold strategic choices should be rewarded; it should not be possible to override them with one sentence. These concerns can easily be addressed directly and do not require abandoning intrinsicness any more than they require banning CPs. Responding to Objections—“The Politics DA is Good to Read About” Despite being the most popular response to the intrinsicness test, this argument is a total non-starter. That a disadvantage spices up the discourse in some way could literally not be less relevant to the threshold for linkage between a policy and an outcome. If this consideration was dispositive, shouldn’t we also reject counterplans that solve a politics advantage on theoretical grounds? More broadly, shouldn’t we then reject any counterplan that solves an advantage someone could argue is educational to read about? Obviously not. No judge would vote for such an argument. It is clearly absurd to pretend things are relevant to whether the plan is good or bad just because they are interesting to read about. But even assuming for the sake of argument that this notion could conceivably withstand scrutiny, the objection still fails. First, politics DAs are stupid. They do not teach you anything valuable. They only brainwash you to buy into a bankrupt horse-race model of political journalism that breeds cynicism and polarization while conveying little, if any, substantive information about the contents of popular proposals. They instill a zero-sum mentality that inculcates reflexive centrism and convinces people their political demands are impossible. Can anyone who debated the stimulus or infrastructure DA actually break down, in detail, what is contained within those packages, beyond “yes/no gas tax,” “yes/no checks,” and “yes/no spending money on (green) roads”? Maybe they could do this better than a random person off the street, but not by much. There is an excellent video[9] by former Wake Forest debater Carlos Maza on this subject. Second, you do not need politics DAs to follow the news. You can just do it. You will get more out of your news diet if you aren’t reading it through the lens of Joe Biden’s political capital. Any former debater will tell you this. If you only have an outlook on politics because of your uniqueness research, your motives are not sustainable, and the outcomes will be totally hopeless anyway. Third, you could read an intrinsic politics DA. You could read elections. The electorate’s response to the plan is not automatically remediable via an intrinsicness test in the same way that an agenda DA might be. Certainly, the AFF could introduce an additional policy to offset the perception of the plan. Such an argument could be addressed by high-quality, specific link evidence about the plan’s effect on the election, coupled with a CP to reciprocally interrogate the plan’s necessity. Responding to Objections—“Intrinsicness is Blippy” This argument is a truism—incomplete thoughts make poor arguments. That is why most intrinsicness arguments currently advanced by debaters would be inadequate under my proposal. The main impetus for this proposal was reciprocity; this lens offers a good way to think about the “blippiness” objection as well. The NEG can’t defeat an AFF advantage simply by saying that it is not intrinsic and should therefore be rejected—they must introduce a complete CP argument, with a text, solvency arguments, and net benefit. Just as CPs with full texts and solvency arguments make a “non-blippy” intrinsicness argument about an advantage, intrinsicness tests with full texts and solvency arguments are “non-blippy,” solve sandbagging, and ensure ideas are sufficiently fleshed-out to debate. Responding to Objections—“Infinitely Regressive” The final objection to intrinsicness that I will address is that it contains the possibility for infinite regression; conceivably, an AFF team could introduce a test, a NEG team could respond by reading a DA to this test, an AFF team could introduce a new test against the new NEG DA, and so on until the 2AR ends the debate with the last move. McKinney’s original article adequately dispenses with this objection, however. This chain of infinite regression is a pure hypothetical that has never occurred and is difficult to even imagine. Moreover, this objection links equally to CPs (one might 2NC CP out of 2AC offense against a 1NC CP, prompting new 1AR offense, prompting a new 2NR CP, prompting new 2AR offense)[10]. Similar scenarios are even possible without resorting to exotic notions like new 2NR CPs—an impact turn debate can also result in regression, with new turns being introduced all the way until the 2AR as each speech impact turns the previous one. This also never happens, but the potential for such a cycle to occur is inherent to finite debate events in which it is accepted that new arguments in the last constructive can be answered by new arguments in rebuttals. At worst, this objection is solved by limiting the introduction of intrinsicness tests to constructive speeches. It does not necessitate discarding intrinsicness altogether. Conclusion At the end of the day, it is essential to remember what detractors of intrinsicness are requesting: to get away with lower quality in their research, less specificity in their evidence and analysis, and a double standard between themselves and their opponents. Many arguments against intrinsicness presented by frantic NEG block speeches on politics fail to provide reasons for their position that do not equally implicate the use of CPs. While there are some justifications for treating the AFF and NEG differently in this context, those justifications are thin and often used as an ex-post rationalization for a reactionary position with little support. By mirroring theoretical limits on NEG CPs for AFF intrinsicness tests, teams can raise the bar for the salience of NEG objections, thus elevating the discourse without letting the most egregious examples of intrinsicness tests through the door. As a final note, I want to briefly mention kritik links. I have not talked about these in this essay; I hope that someone better positioned to comment on the mechanics of linkage in kritiks of policy and kritikal AFFs alike will eventually do so. While it may be possible to transpose the language of intrinsicness into K debates and simply evaluate linkage as a question of necessary connection rather than necessary and sufficient causality, doing so begs the question of many common NEG framework arguments which are beyond the scope of this piece to address. For now, suffice it to say that the proposed standard should not be automatically applied to kritikal discussions, as doing so without interrogation would prematurely discard potentially distinguishable NEG objections. [1] T. A. McKinney 91, “Rehabilitating Intrinsicness,” in Addressing Homelessness: Social Services in the 1990s, the Wake Forest Debater’s Research Guide, retrieved from the Digital Speech and Debate Initiative Theory Library [2] I considered suggesting that intrinsicness tests should be allowed to generate offense insofar as that offense requires the presence of the plan. I decided in favor of a categorical rule for two reasons. First, because the latter formulation would effectively obviate the sufficiency requirement for advantages, undermining the benefits of strict intrinsicness requirements for AFF/NEG reciprocity. Second, because allowing intrinsicness tests to generate offense would blur the otherwise clear line between an intrinsicness test and a conditional plan amendment. [3] Merriam-Webster no date, “Intrinsic,” https://www.merriam-webster.com/dictionary/intrinsic [4] Dan W. Brock 73, “Recent Work in Utilitarianism,” American Philosophical Quarterly, vol. 10, no. 4, [North American Philosophical Publications, University of Illinois Press], 1973, pp. 241–276 [5] McKinney, pp 5-6 [6] See the appendix for a more detailed breakdown. [7] Robert P. Newman 65, “The Inherent and Compelling Need,” Journal of the American Forensic Association, 2, 66-71. [8]A. N. Kruger, cited by Kathryn M. Olson 8, “The Practical Importance of Inherency Analysis for Public Advocates: Rhetorical Leadership in Framing a Supportive Social Climate for Education Reforms,” Journal of Applied Communication Research, No. 36, Iss. 2, 219-241. [9] Carlos Maza 19, @gaywonk, “Why You Still Don’t Understand the Green New Deal,” 03/11/2019, YouTube, https://www.youtube.com/watch?v=UpqFaf8vQfk [10] McKinney, page 3 Appendix - 2NRs by Coaches Poll Teams, 20-21Breakdown of 2NRs against policy AFFs by teams ranked in the top 25 by the last Coaches Poll of the 20-21 high school policy debate season. Totals calculated by “2NR / argument”—a 2NR containing two Politics DAs, for example, counts as two “politics 2NRs,” even though they occurred in the same speech. 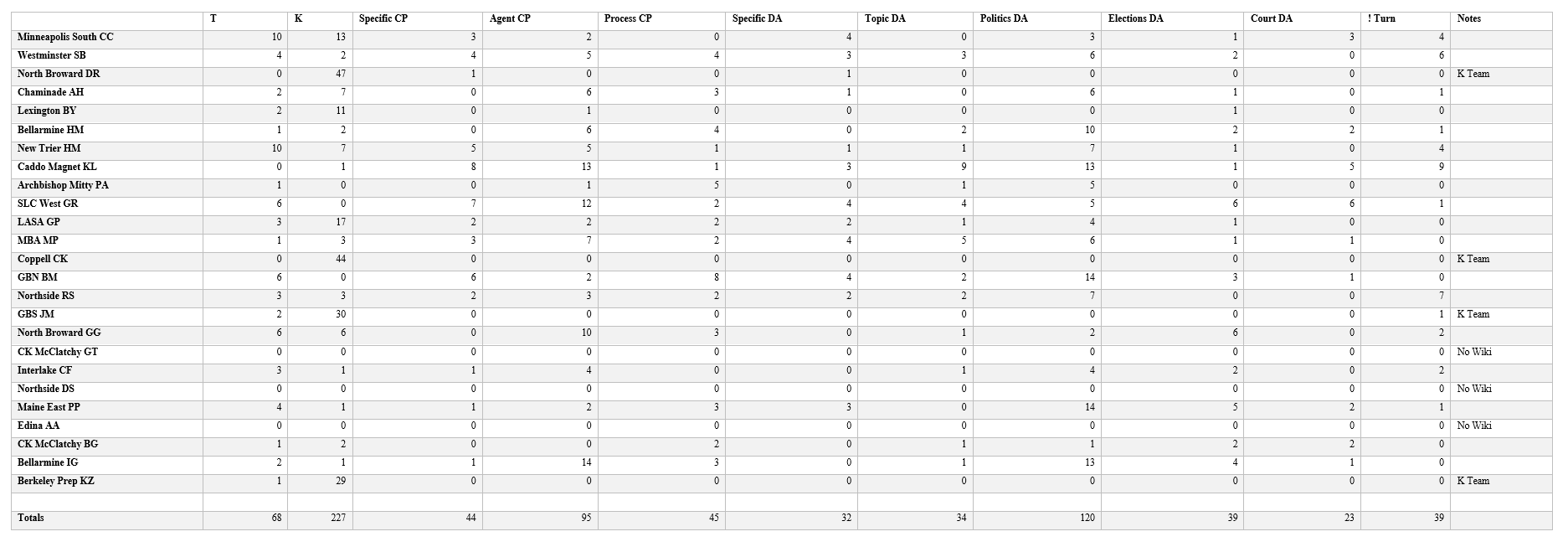 Breakdown of 2NRs by teams that go for Kritiks against policy AFFs in less than 80% of debates ranked in the top 25 by the last Coaches Poll of the 20-21 high school policy debate season (excluding North Broward DR, Coppell CK, GBS JM, Lexington BY, and Berkeley Prep KZ). Same method as above. 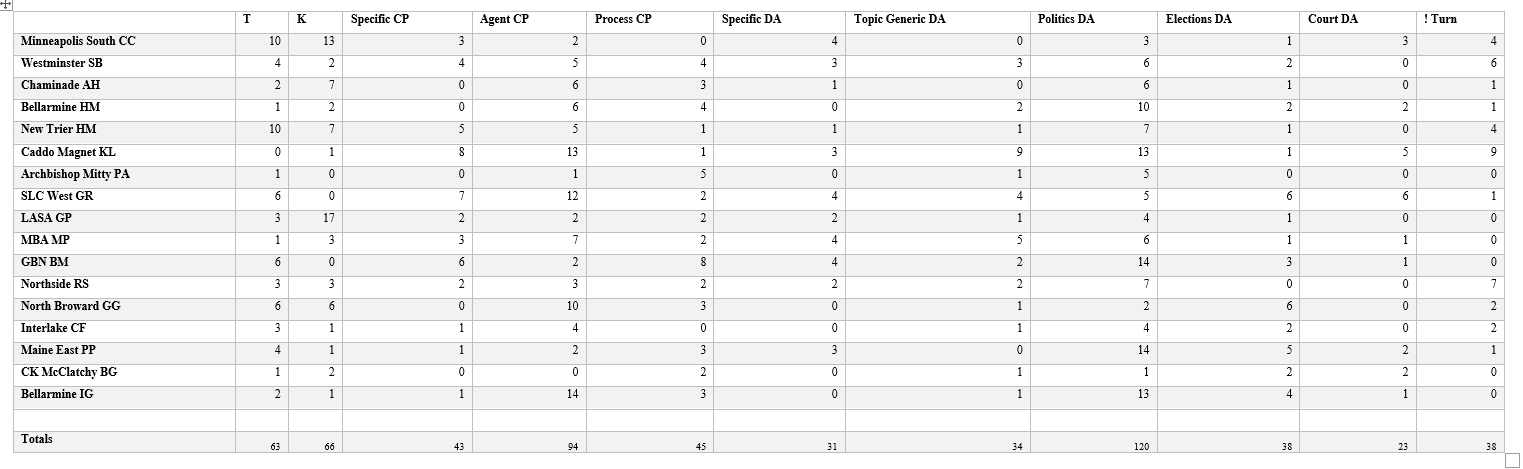 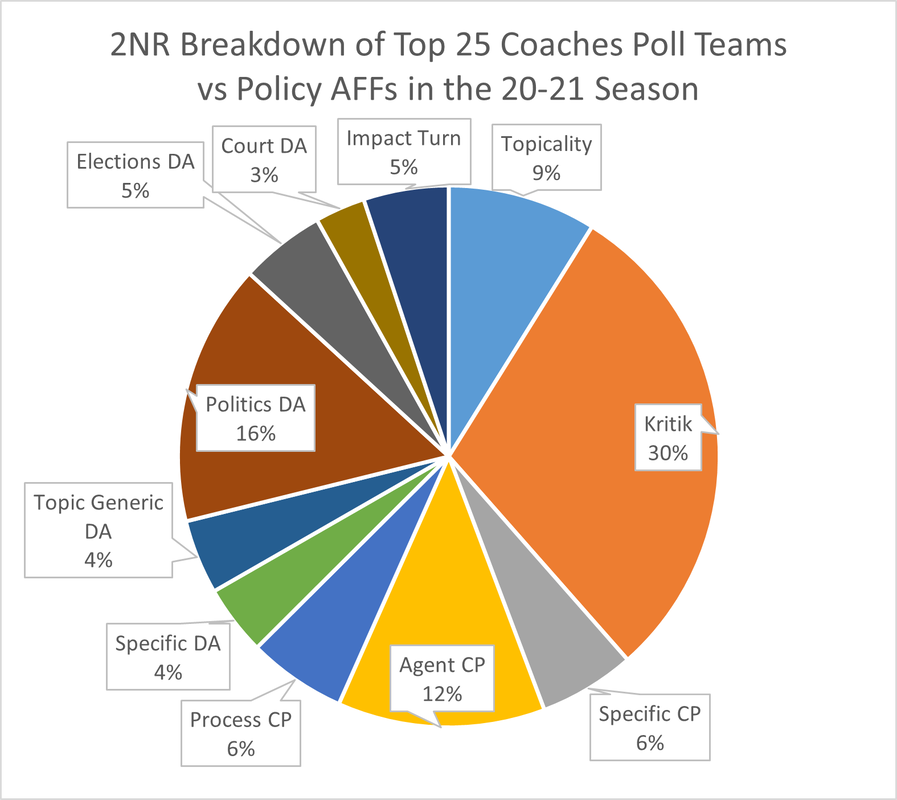 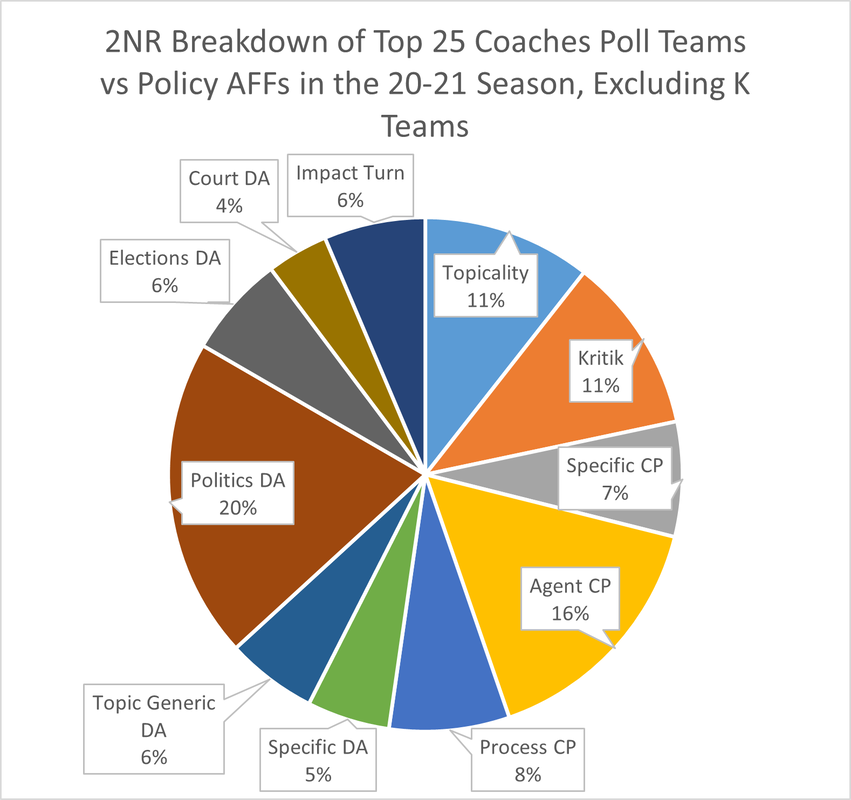 The NDT is over. Many seasons have come to an end. Everyone can take a breath. You made it to the end. An honest to goodness season occurred over zoom. There are no asterisks here. People found a way to work hard when some were never in the same room as their coaches or teammates all season. Really incredible. There will be more earnest posts in the future, particularly about the future of debate, but for now here is what caught my eye. 1. IanM If you were an oddsmaker and you wanted to improve your chances of your team winning, debaters like IanM are top 5 draft picks. College novice to NDT elims. Warms my cold dead heart every time. How many other folks are there on college campuses who never knew what debate was in high school that could have a similar story? I grew out of imprinting initials on cards a few years ago. I would wager it was correct to do so. Two justifications for it are: imprinting is accountability (what if IanM cut Drezner 15 or whatever it was??) and makes it easier to figure out exactly how much work someone is doing. At Liberty I found this useful because with a novice-based team it clarified how much work was required at varying levels of seriousness. The downside is it looks bad, it signals information to your opponents (most isn’t helpful, but the earnest argument is “oh look they only go for cards they cut, none tagged by other people, so I will change coverage accordingly”) and leads to clout-chasing toxicity within a team. You can tell who cuts a lot of cards and who doesn’t anyway – imprinting cards and keeping score is unnecessary. So, I think the downside outweighs, but I like the signaling done by the IanMs and KENs of the world who are cutting a lot of cards for their team. 2. Kelly Phil She debated on a flipped schedule while in Taiwan for a tournament that lasts like 12 days and made it to quarters?? I hazard to say we may not see anything quite like that again at the NDT. Incredible work from the frosh. 3. 11 judge panels What better way to hedge than let 11 people judge your debates? 11 chances to roll the dice! I love the chaos potential. The best part is that this 11 judge panel clocked a very reasonable decision time compared to some of these other elimination panels. 4. Dartmouth cards I love that they are all formatted different. I like how they don’t look like other teams’. I like how the length is totally random. Would I be so bold as to put money on the quality of card that I am getting? I sure wouldn’t. Sometimes you get something awesome, sometimes you get two lines of a Raam fever dream. But it is the journey that matters! 5. 8-0, 19 ballots My debate career was not the most storied. One fun fact is that my senior year, I went 6-2 with 12 ballots at the NDT. I believe that is the only time that score has been registered. So when I saw 8-0 with 19 registered by Kansas BF, I thought that surely a jackpot had been hit and a unique NDT score had been registered. Not so! In 1977, Northwestern Love and Singer also registered an 8-0 with 19 ballots. They beat Middle Tennessee and lost to Redlands in the quarters (NDT cleared to octafinals in this era). For the real history nerds out there, 8-0 with 18 was done twice too. Michigan SW (Stoughton and Wexler (of HRIA CP fame)) in 1998 and in 2003 by Georgia PR (Powers and Ramachandrappa) 6. Flexy Peens I would stake my life on two claims. First, everything said about flexible response seemed banal. There are O’Hanlon cards on every topic, don’t fall prey to their siren song. Second, Peens was the best area to be affirmative. If you know you know. I was very conflicted when Georgetown read flexible response for Peens. It is like this:  But an affirmative.
7. Maraj 20 I would read up on Louis Maraj’s CV and the people they cite and who cite them. I would speculate it could be the next big thing, a la Grove 20. 8. Fucking Fleming T-there are only four affirmatives. It is the quarters of the NDT. Everyone is sitting around past the four-hour mark waiting for Fleming to decide. What would the payout have to be for you to stake anything against Fleming sitting on the bottom of a 4-1? I think it was clear what was going to happen after about 20 minutes. Seriously though, let’s time elims at like 3 hours, maybe 3:15. Gotta cap those diminishing returns somewhere. I guess we can exempt the finals. 9. Schedules I'd bet dollars to doughnuts that everyone has an opinion on the way schedules work. The issue we run into in debate is that we aren’t great at dialogue and hashing out a consensus. I think we can do it! We can make progress on schedules. The first question: what is the baseline amount of time needed in a preround? I propose 30 minutes. I am sure this does not comport to the way some teams handle their business now, but as a bar any team could learn to live and thrive with, 30 mins of prep before a debate is adequate. The real thing to hash out is what values warrant deviating from that baseline. For example: Round 7 and 8 largely determine who clears. Should there be more prep time? Some rounds are impacted by food breaks. More time? Elims are more important to prelims. Should prep time for round 2 and the octafinals be the same? You can’t be eliminated from the tournament in round 1 or 2 (you could draw the line to include round 3 maybe). Tournaments (mine included) apply the same prep to all rounds. I can’t say this maximizes any value beyond like…if you set the bar at like 40 minutes and do it consistently then people do not complain. I can’t say it is achieving good values though. The rub is that the days are very long, and we have to reckon with it. 10. So much topicality, so little topic Ugh, I won’t beat a dead horse. I am not going to go for broke. It is not in the cards. But wowza – so much topicality about nothing. It will never not be funny that this was supposed to be the DA’s topic. 11. More History Non-male top speakers before 2021: Patricia Stallings from Houston in 1957, Gloria Cabada from Wake Forest in 1988, Stephanie Spies and Ryan Beiermeister from Northwestern back to back in 2011 and 2012, Natalie Knez from Georgetown in 2018. Black top speakers before 2021: Rashid Campbell from Oklahoma in 2014, and Devane Murphy from Rutgers in 2017. Azja Butler from Kansas is the sixth non-male top speaker, the third Black top speaker and the first ever Black woman to win top speaker at the NDT. One of the reasons the NDT always gets the juices flowing, even for people out of the activity for decades, is that the NDT is what shapes the history books more than anything. As a debate lifer I do not think you can recognize the special team efforts required to carve out a place in history enough. Special kudos to Jyleesa Hampton. She started coaching in 2015-16, and you would be hard pressed to find a coach whose teams have put up better results. Other fun ones you may not have ventured to guess. Kansas had the top two speakers BUT they were not partners. A school has definitely had the top two speakers before (Rutgers MN, Harvard BS, NU BK, NU GS to be precise). This is the first time a school had the top two speakers from different partnerships. No amount of going for T-substantial could hold Nate Martin down! The other, more obvious historymaker is Pitt MO. This blog has been on the record that the heg good affirmative was not what it seemed against the K, and if equally debated the Neg should find a way to win. I believe that is what happened in the doubles vs Emory. It would be difficult to find an NDT semis performance this impressive, given the combination of their low seeding with the strength of opposition faced. The college policy alums Facebook page certainly did dig up some interesting examples. Kansas BR in 2016, as a non-bid team that made the finals, is certainly up there. Trevor Wells from Facebook: Harvard KT (Karem & Tushnet), 1992. 11th bid, 15th seed. Beat the #18 seed (Pittsburgh BR) in the doubles, and then unleased some huge wins in the octas (Texas GM, the #2 seed and #5 bid), quarters (Wayne State AG, the #10 seed and #12 FRALB [which seems so low in retrospect; those guys were fire]), and semifinals (Dartmouth AL, the #3 seed and #1 FRALB), before losing a 6-1 decision in the final to Georgetown AK (the #8 seed). The only other history note I have at the moment: 3 of the semifinals teams had a Black debater on it. Easily could be the first time such a thing has happened. 12. Unbroken Aff Bracket The people in the trenches report they were unenthused by the affirmatives that were broken at the NDT. Too predictable. Too banal. By popular demand – if you want to send me a 1AC for an affirmative that was unbroken at the NDT, I will create a Bracket (with a capital B that…) and let the good people decide if there are any true innovators among us. Let the chips fall where they may. Everyone put their cards on the table. Cowards can’t block warriors. Very surreal NDT. Congratulations if your season concluded. You made it. This post occurred to me around the time water resources was announced as next year’s high school topic, but I had not sat down to write it until now. There are two areas I wanted to speak to. One concerns discourse on whether a topic is good or bad as it is happening. The other concerns what is said when people get in a mood to speculate on what makes a topic good. I don’t have a treatise on these subjects, just some things that need to be said.
1. Researching CJR is Good If you are actively involved in this topic and you are not a fan of it, I am not sure we can really relate to one another. Topics that make debaters learn about key parts of society are good. This is one of the reasons why healthcare was a good topic; if you walked away knowing what all the words around insurance mean, that is a big step up from the general public. Is the topic very large? It sure is. A nice part of the topic has been that every time I go searching for negative arguments, I do not know what they are going to be, but I do find something. That is a fun dynamic. Did the affirmative need to be allowed to criminalize stuff? No, but a post for another day about topicality. The K for the negative is very good, but not a lot of teams cared to learn this flexibility and the affirmative has said nothing about it all year. Nevertheless, it is a good core debate. Is it the world’s best topic? Not necessarily, mainly because it was too big to to allow specific preparation across the board. Specific arguments exist, there are just too many of them and little overlap. Overall, though, it was a strong domestic topic. 2. The Water Topic is Big Like, really big. The mechanism of protection includes everything. Giant themes around climate change, oceans, agriculture (and regulating other industries), and deforestation are likely to be fair game. The States CP could do some more work than it did on CJR. If you decided to not be a flexible team and incorporate the K into your negative strategy on CJR, I would strongly advise you do it on the water topic. There will be negative arguments, but there won’t be strong generic arguments that apply across most of the topic. 3. Projecting Topics This next part is going to be focused on college debate. The first thing we have to recognize is that the topic committee’s job, definitionally, is impossible. What people think the topic is going to be in May is not what is going to happen in the first semester. This dynamic is demonstrated by a lot of other games, mainly deckbuilding games. The limited resources of the topic committee can’t contain hundreds of people doing way more research and trying to be as strategic as possible. Recognizing this dynamic is important because it reveals the flaw in a popular way to project topics. That approach is to say here are the big affirmative cases and here is a topic disadvantage that connects them that the negative can lean on. I think the alliances topic makes clear the issue with this approach. Topic committee work was focused on attempting to create a limited number of affirmatives that guaranteed the negative a certain amount of ground. What happened was the affirmative ground was sub-optimal, the affirmative was not limited because they never are, and the promises of negative ground did not materialize when the affirmative began to squirrel. Caring about this dynamic at all misunderstands how a lot of people experience the topic. A lot of debaters are not worried about writing ten policy affirmatives. A lot of teams don’t care about what generic applies when the Pacific Entrapment Aff is broken on them because that isn’t going to happen to them. A lot of people care about how accessible the topic is to people new to the activity or those who are developing their skills. A lot of people care about what constitutes affirmation on a given topic. They do not seem to ultimately care about writing negative generics, since a lot of teams do not do that but copy from others. They do not seem to care about writing a million affirmatives, their teams read the same affirmative for 90% of their debates. Personally, I like researching things I have not researched before. I also enjoy topics where when I go searching for something, whether I have a guess on what that something is or not, I come back with something useful. I think people may have deluded themselves on alliances, because what y’all keep coming back with are not really affirmatives in the sense that they do all of the things required by the resolution, check the boxes of defeating core Neg positions, and are supported by evidence. Judging topics on things like:
I think prioritizing these kinds of questions may result in toning down the complexity of resolutions, particularly mechanisms. This may result in larger, but more interesting and easier to research topics. The main priority should be establishing a topic that can help sustain new participation in the activity. It should not be how a handful of schools using full time debate coaches (that do not teach or are students etc.) are going to find something to say for the NDT. Those schools (Kentucky is obviously among them) are going to find shit to say, they don’t need any catering. There are many schools and students who can have a good time with debate that will never ever care about some of the questions that so dramatically drive the topic process. Didn’t you say large topics like CJR got unwieldy though? It is not analogous to college because the high school topic process greatly differs from college. There is a lot of room to roam between what college has been doing and what high school does to itself. The relevant lesson to take away from CJR is that the research is accessible and relevant to people’s lives and it is very simple to carve out space where you don’t have to worry about whether rogue AI should receive the death penalty or not. Buttttttt, if your topic is big won’t the under-resourced debaters hate showing up with nothing to say? That is the squo. Topics break now. There are piles of nonsense. Sometimes, we make simple and large topics like climate. People can debate about carbon pricing if they want or they can delve deeper and there are still good debates. Other times we give them this: Resolved: The United States Federal Government should substantially increase statutory and/or judicial restrictions on the executive power of the President of the United States in one or more of the following areas: authority to conduct first-use nuclear strikes; congressionally delegated trade power; exit from congressional-executive agreements and Article II treaties; judicial deference to all or nearly all federal administrative agency interpretations of statutes and/or regulations; the bulk incidental collection of all or nearly all foreign intelligence information on United States persons without a warrant. Or this: Resolved: The United States Federal Government should establish a national space policy substantially increasing its international space cooperation with the People's Republic of China and/or the Russian Federation in one or more of the following areas: • arms control of space weapons; • exchange and management of space situational awareness information; • joint human spaceflight for deep space exploration; • planetary defense; • space traffic management; • space-based solar power. Or this: Resolved: The United States Federal Government should reduce its alliance commitments with Japan, the Republic of Korea, North Atlantic Treaty Organization member states, and/or the Republic of the Philippines, by at least substantially limiting the conditions under which its defense pact can be activated. These aren’t pot shots at the topic committee. They do an impossible task with the hand they are dealt. We should be changing the inputs. The topic should focus on growing the sustainability of the activity, not worry about how the most well-resourced schools are going to inflict suffering on one another. |
AuthorI am Lincoln, retired debate coach . This site's purpose is to post my ramblings about policy debate. Archives
November 2022
Categories |
||||||||||||||||
 RSS Feed
RSS Feed