|
Cannot say I am wild about hearing that the wiki crashes over the last 3ish months have been due to someone deploying a spider to download all the documents back from 2012. Then I hear that this "aggregation service" is being sold for profit. Not wild about that either. So I thought I would offer a little corrective, free of charge. The wiki is great. Open source is great. The people out here chopping cards are great. This is not an area where we need novel ways to make money. One issue with the wiki in the era of open source is that its search function isn't very good. It takes you to a wiki page, but then you just have a bunch of documents and you don't know which one to click on. Let me help you with that. There are over 4,000 wiki docs in this folder, feel free to download them: https://www.dropbox.com/sh/xaub80x3n9a47hs/AACSuAXKPb08tuTPEiWP5Zmma?dl=0 It is not 280,000+ unique cards, and not every document on the wiki. And has no Kentucky docs in it (which is a blessing or a curse depending on who you ask). But it is a bunch of cards since Trump got elected. How does one search all these documents? That is where Doc Fetcher comes in. http://docfetcher.sourceforge.net/en/index.html You have to make sure java is up to date then you download doc fetcher. 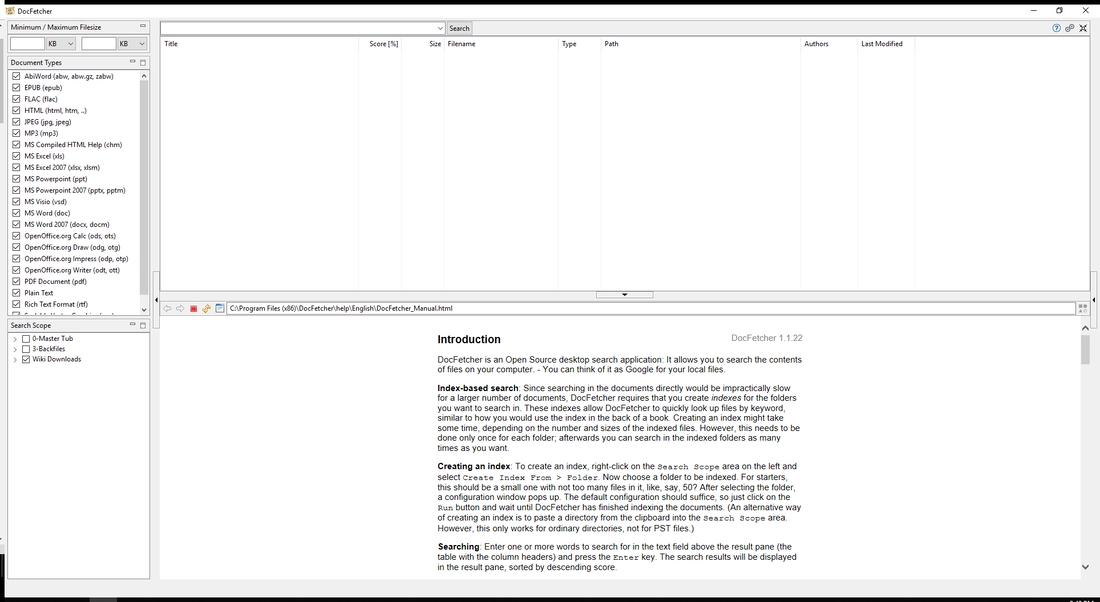 In the search scope on the bottom left there you create index form. You pick the folder you want it to scan then it is going to take sometime running. It is scanning that folder and indexing all the documents in it. What happens is you can search a folder, but it lets you look into the document. 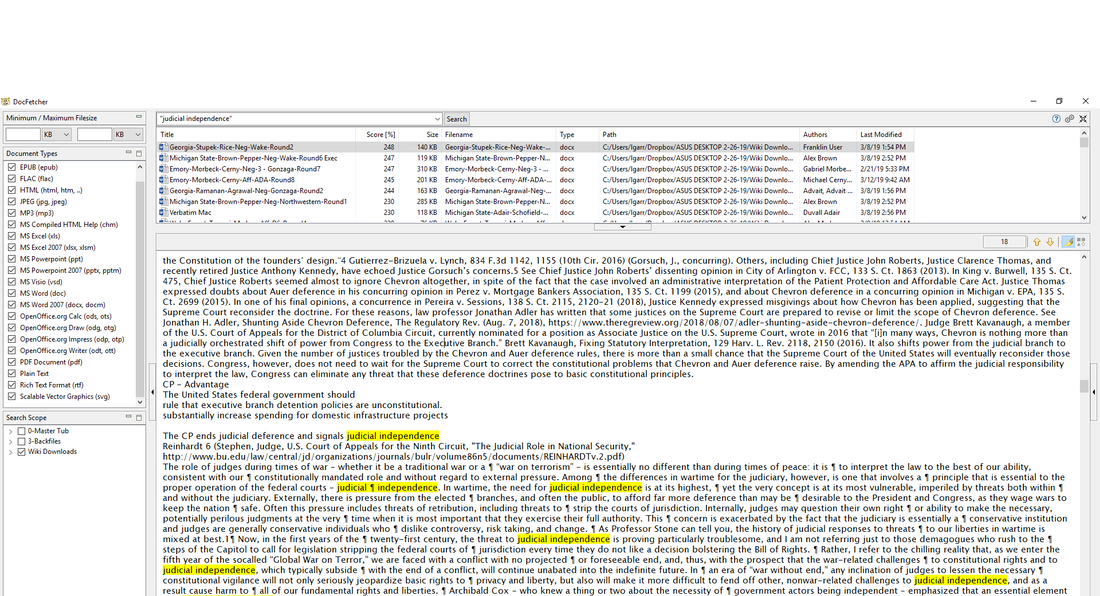 The little up and down arrow on the right center of the screen lets you search for each occurence of the word or phrase you typed in.
So I would use the dropbox folder and docfetcher if you know someone has read a card about something but the wiki proves too cumbersome to navigate. Comments are closed.
|
AuthorI am Lincoln, retired debate coach . This site's purpose is to post my ramblings about policy debate. Archives
November 2022
Categories |
 RSS Feed
RSS Feed